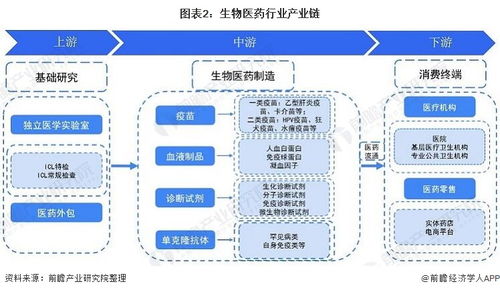
從單體到智能 圖解分布式架構演進與人工智能應用的軟件開發
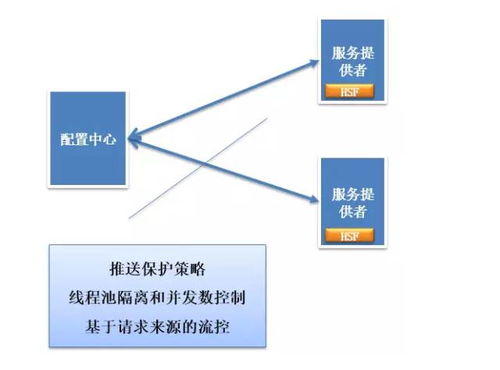
在當今以數據驅動和智能化為核心的技術浪潮中,分布式架構已成為構建大規模、高可用性系統的基石,而人工智能(AI)的深度融合,正引領著軟件開發進入一個全新的范式。本文將通過圖解與解析,梳理分布式架構的發展脈絡,并探討其在人工智能應用軟件開發中的關鍵作用與最新實踐。
一、 分布式架構的演進圖譜
分布式架構的演進并非一蹴而就,其發展歷程清晰地反映了業務復雜度與數據規模的爆炸式增長。
第一階段:單體架構 (Monolithic Architecture)
- 圖示核心:一個單一的、龐大的代碼庫,包含所有功能模塊(如用戶界面、業務邏輯、數據訪問層),通常部署在一個進程中。
- 特點:開發簡單,初期部署快。但隨著功能增加,代碼變得臃腫,維護困難,牽一發而動全身,擴展性差(只能垂直擴展)。
第二階段:垂直分層架構 (Layered Architecture)
- 圖示核心:在單體內部,按關注點分離為表現層、業務邏輯層、數據訪問層等。這是架構清晰化的第一步,但本質上仍是單體。
第三階段:面向服務架構 (SOA, Service-Oriented Architecture)
- 圖示核心:系統被拆分為一組松耦合的“服務”,通過企業服務總線(ESB)進行通信和集成。服務通常較粗粒度(如“用戶服務”、“訂單服務”)。
- 演進意義:實現了服務的復用和業務的靈活組合,但ESB可能成為性能和單點故障的瓶頸。
第四階段:微服務架構 (Microservices Architecture)
- 圖示核心:SOA思想的精細化與實踐化。系統被拆分為一組更小、獨立部署、圍繞業務能力構建的細粒度服務。每個服務擁有獨立的數據存儲,通過輕量級協議(如HTTP/REST, gRPC)直接通信。
- 關鍵賦能:獨立開發與部署、技術異構性(不同服務可用不同語言/框架)、彈性擴展。但帶來了服務治理、分布式事務、監控等復雜性。
第五階段:云原生與服務網格 (Cloud-Native & Service Mesh)
- 圖示核心:微服務部署在容器(如Docker)中,由編排系統(如Kubernetes)統一管理。服務間的通信、安全、可觀測性等“非業務功能”被下沉到服務網格(如Istio)這一基礎設施層。
- 演進意義:將開發人員從復雜的分布式通信治理中解放出來,更專注于業務邏輯。實現了架構的徹底解耦與運維的自動化。
第六階段:無服務器與事件驅動 (Serverless & Event-Driven)
- 圖示核心:函數即服務(FaaS)成為計算單元,由云平臺根據事件觸發(如HTTP請求、消息隊列事件)動態調度運行,按實際使用計費。后端服務(BaaS)提供托管服務。
- 演進方向:進一步抽象基礎設施,追求極致的彈性與成本效率,適用于異步、事件驅動的場景。
二、 人工智能應用軟件開發的分布式架構挑戰與融合
人工智能應用,特別是涉及大規模模型訓練、實時推理、流式數據處理的應用,對分布式架構提出了獨特需求并與之深度融合。
1. 數據處理與訓練階段:計算密集型分布式
挑戰:海量訓練數據、巨大的模型參數(如大語言模型)。
架構融合:
* 數據并行:將訓練數據分片,分布在多個計算節點(GPU/TPU集群)上,同步訓練同一模型。
- 模型并行:將巨型模型本身的不同層或部分拆分到不同設備上。
- 流水線并行:將模型按層分段,像工廠流水線一樣在不同設備上并行處理不同批次的樣本。
- 圖解示例:一個由參數服務器(PS)或All-Reduce通信模式連接的龐大計算集群,協同完成分布式訓練任務。
2. 模型部署與推理階段:高并發、低延遲服務化
挑戰:將訓練好的模型以API形式提供穩定、高效、可擴展的在線預測服務。
架構融合:
* 模型即服務 (MaaS):將模型封裝為獨立的微服務。利用Kubernetes進行彈性伸縮,根據請求量自動增減模型服務實例。
- 服務網格賦能:通過服務網格管理模型服務間的流量路由、A/B測試(用于模型版本灰度發布)、熔斷和限流,保障推理服務的穩定性。
- 邊緣計算:對于實時性要求極高的場景(如自動駕駛),將輕量級模型部署在邊緣設備,形成云-邊-端協同的分布式推理架構。
3. 特征工程與數據流:實時事件驅動
挑戰:AI應用往往需要處理實時數據流,進行特征計算并觸發模型推理(如推薦系統、欺詐檢測)。
架構融合:采用事件驅動架構。使用消息隊列(如Kafka, Pulsar)作為中樞,連接數據源、流處理引擎(如Flink, Spark Streaming)進行實時特征計算,并事件觸發推理服務。這本質上是分布式的、松耦合的流水線。
4. 機器學習工作流編排:分布式管道
挑戰:AI開發包含數據收集、清洗、訓練、評估、部署等多個步驟,需要自動化、可復現的流水線。
架構融合:采用如Kubeflow, MLflow等MLOps平臺。這些平臺基于Kubernetes,將每個步驟(如數據預處理、模型訓練)封裝為可獨立運行、可伸縮的容器化任務,并通過DAG(有向無環圖)進行編排,構成一個分布式的工作流系統。
三、 未來展望:智能化與分布式的共生演進
分布式架構與人工智能正在形成正向循環:
- AI for Infrastructure:利用AI來優化分布式系統本身,如智能流量調度、故障預測、資源自動擴縮容,實現“自動駕駛”的運維。
- Infrastructure for AI:更強大、更易用的云原生分布式基礎設施(如專為AI設計的高速互聯、異構計算調度),持續降低大規模AI應用開發與部署的門檻。
結論:分布式架構的演進,從解耦單體到云原生智能化,其核心驅動力始終是應對規模與復雜性的挑戰。而在人工智能時代,分布式架構不僅是承載AI應用的“軀體”,其自身也正在吸收AI技術變得更具“智慧”。對于“技術頭條”的讀者和人工智能應用軟件的開發者而言,深刻理解這一共生演進關系,掌握將分布式系統設計模式與AI工作流相結合的技能,是構建下一代智能、彈性、可靠軟件系統的關鍵所在。
如若轉載,請注明出處:http://m.ttm123.cn/product/20.html
更新時間:2026-04-10 12:37:33